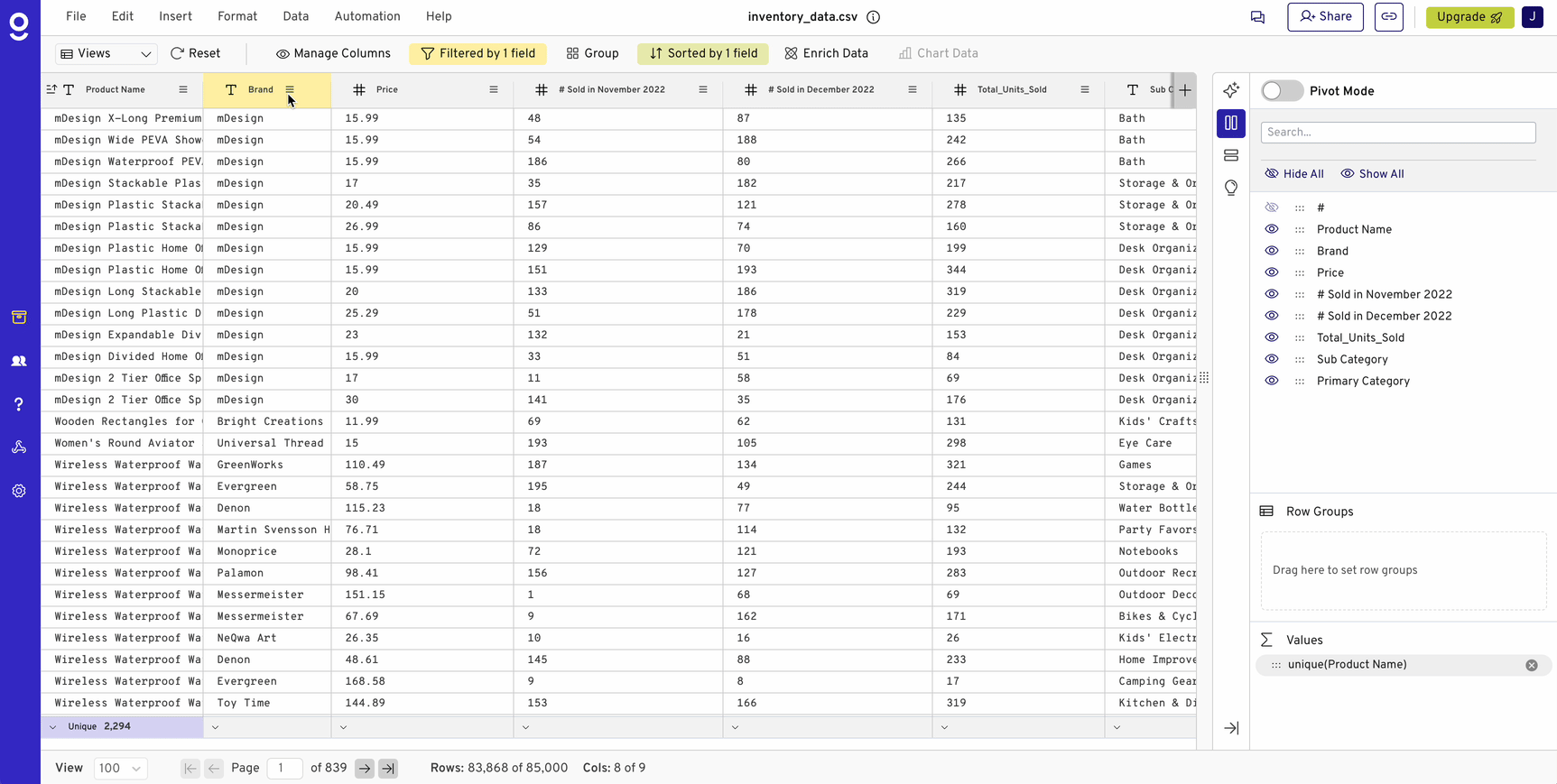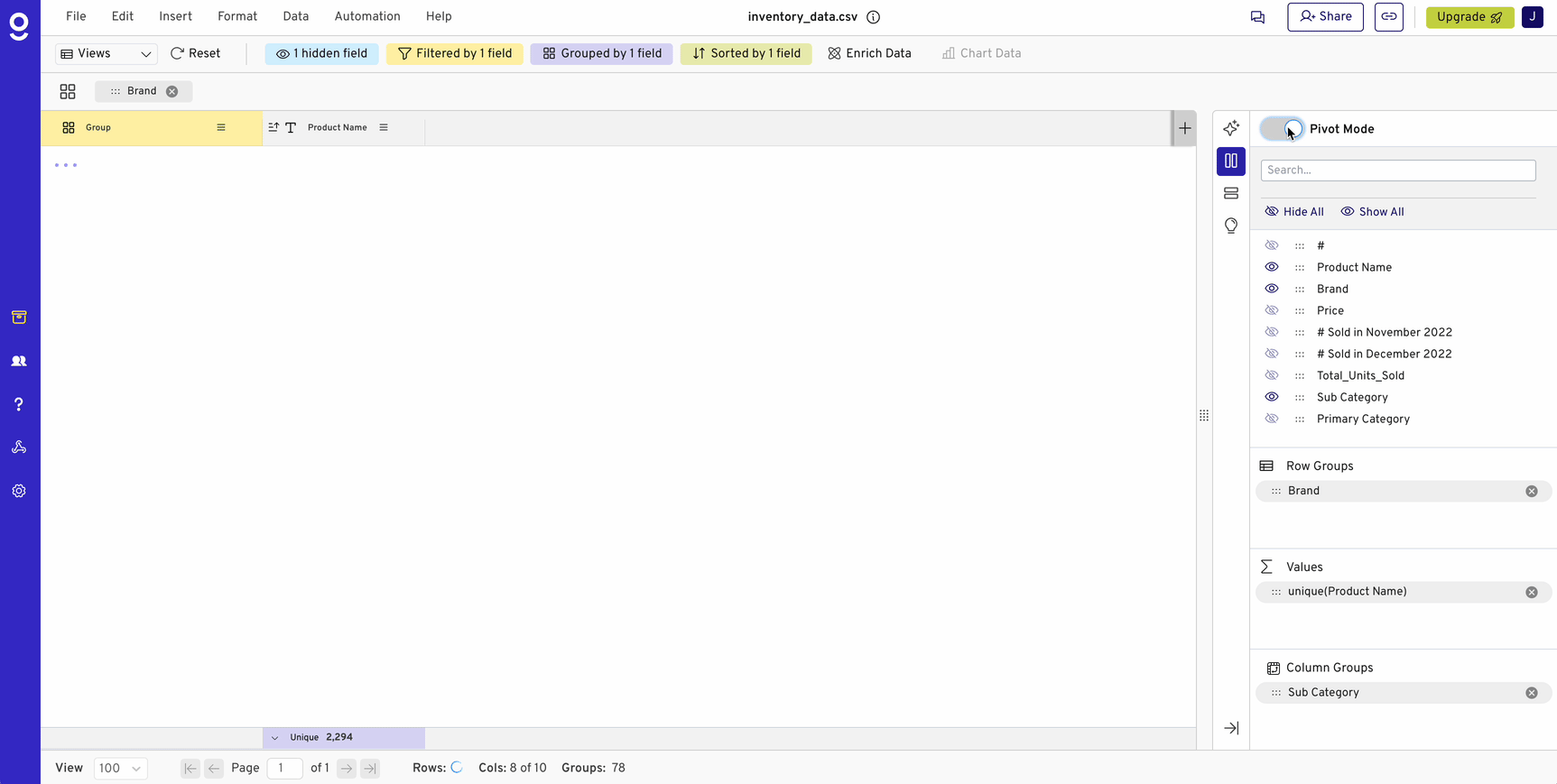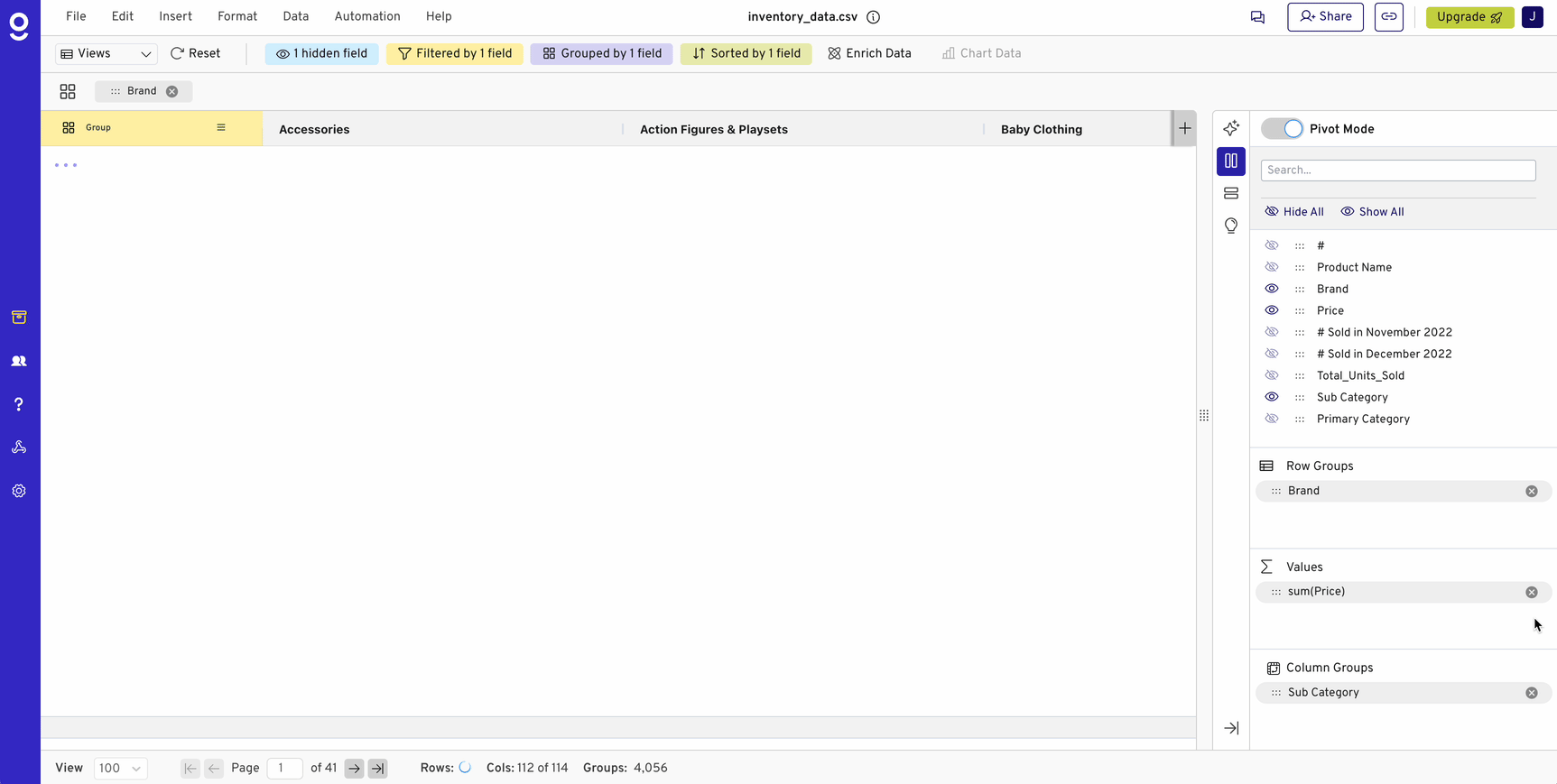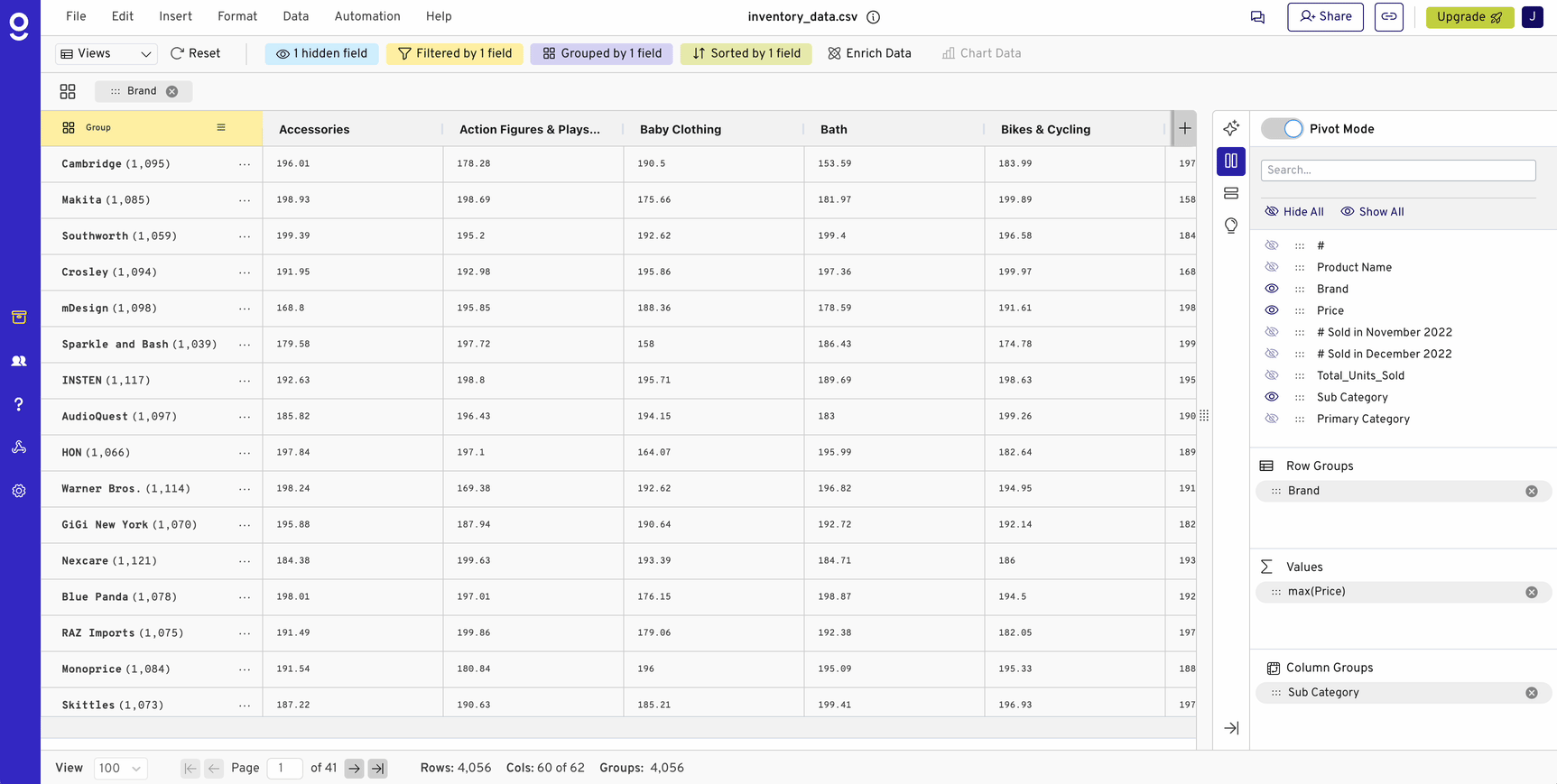



Pivot tables are a must-have tool for analyzing data, enabling quick grouping, filtering, and aggregation. But as organizations increasingly use databases and data warehouses like Snowflake, Redshift, and BigQuery to handle massive datasets, traditional spreadsheets start to show their limitations. Excel, Google Sheets, and similar tools aren’t built for datasets with hundreds of millions of rows, yet many teams still rely on them for data analysis.
In this post, we’ll explore common ways users tackle pivot tables on large datasets in spreadsheets, some of the trade-offs involved, and when it might be time to consider alternative tools.

Why Spreadsheets Struggle with Large Database Exports
Spreadsheets are inherently flexible, making them popular for pivot tables and quick calculations. However, tools like Excel or Google Sheets struggle with today’s large-scale data demands, especially when dealing with data exports from warehouses. Here are some of the challenges users face:
Row and Cell Limits
Most spreadsheets have row and cell limits, making it difficult to load large datasets directly. Excel has a limit of around 1 million rows, and Google Sheets has a maximum of 10 million cells per sheet. For databases like Snowflake or BigQuery, datasets often exceed these limits by orders of magnitude.
Even if the data volume is within spreadsheet limits, performance can slow significantly, with calculations and data refreshes taking considerable time.
Data Freshness and Syncing
Databases are dynamic, often updating in real-time or on regular schedules. Exporting data to a spreadsheet introduces the challenge of data freshness, as static exports must be manually refreshed to stay current. This process can be cumbersome and repetitive, making it impractical for ongoing analysis or frequently changing data.
Manual Aggregations and Pivoting
Pivot tables in spreadsheets can handle basic groupings, but large datasets require additional work. Analysts may need to create multiple pivot tables on filtered subsets of data or break down data into smaller chunks that fit within spreadsheet constraints. This approach is error-prone, as each subset must be consistently organized and filtered.
Limited Drill-Down Capability
Drill-down capabilities in spreadsheets are limited, especially for complex or multi-dimensional datasets. Users often work across multiple tabs or reference external sources, reducing efficiency. As a result, quick analysis—like examining transactions within a high-level summary—becomes a tedious process.
Common Workarounds for Large Database Pivot Tables in Spreadsheets
Despite these limitations, many teams use workarounds to analyze large datasets in spreadsheets. Here are a few approaches commonly used by data analysts and their pros and cons.
Exporting Data in Segments
By breaking down data into smaller segments—such as by date range, product category, or region—users can manage datasets in more digestible portions.
Pros: Allows data to fit within spreadsheet row limits, making it easier to analyze segments.
Cons: Requires multiple exports and increases the risk of inconsistency. Segmenting data also makes it harder to view high-level summaries.
Using External Tools to Pre-Aggregate Data
Some analysts create SQL queries or use tools like Power BI or Looker to aggregate data within the database, generating summaries or rolling up data before exporting it to a spreadsheet. This reduces data volume and keeps only the essential information.
Pros: Simplifies large datasets, enabling pivot tables on pre-aggregated data within spreadsheets.
Cons: Limits flexibility and reduces the ability to drill down into raw data. Each new aggregation requires re-querying the database, slowing down analysis.
Linked Spreadsheet Tabs for Distributed Analysis
Users may split large datasets across several tabs or even separate spreadsheet files, linking them to create a master view. By doing so, analysts can create smaller pivot tables for each subset and link them to a main summary page.
Pros: Helps manage data size constraints and provides a consolidated overview.
Cons: Linking multiple tabs can reduce performance, especially with real-time updates. It also increases the risk of outdated links and missing data across sheets.
Using Add-Ons for Direct Database Connection
Some spreadsheet applications have add-ons or integrations that allow direct connections to databases. Google Sheets, for example, has a BigQuery connector, and Excel offers Power Query. These add-ons can pull data directly, enabling more frequent refreshes.
Pros: Provides more current data without constant exports, reducing manual tasks.
Cons: Row and cell limitations still apply, and large-scale queries can strain performance. Automated data pulls may still lag, especially with complex datasets.

Basic Excel Pivot Table Courtesy of Microsoft Support
When to Consider Alternative Tools for Pivot Table Analysis
Although spreadsheets are indispensable for many data tasks, they may not be suitable for every data size or use case. For those who frequently handle large datasets or need real-time analysis, a tool purpose-built for pivot tables on large data can be a game-changer. Platforms like Gigasheet offer a familiar spreadsheet-like interface for pivot tables that scales with large datasets from various data sources, including Snowflake, BigQuery, and Redshift.
For instance, Gigasheet supports true ad hoc pivoting, allowing users to create dynamic groupings and filters without preconfiguring tables. It also enables drill-downs to row-level details, letting users explore data deeply without reaching for a separate BI tool. And if you’re specifically interested in Snowflake pivot tables, check out this post on Gigasheet's Snowflake pivot table capabilities for more on tackling Snowflake data with ease.
Additional Resources for Handling Big Data in Spreadsheets
For those who still rely on spreadsheets but want to optimize for large data, here are a couple of helpful resources:
Working with Big Data in Google Sheets: Google’s guide to handling larger datasets, including tips on using BigQuery connectors and optimizing formulas for performance.
Using Power Query in Excel for Data Transformation: Learn how to pull and aggregate data from various sources directly within Excel, enabling smoother data preparation workflows.
Conclusion
For database users relying on spreadsheets, pivot tables on large datasets can be complex, especially when balancing data size with analytical flexibility. Workarounds like exporting in chunks, pre-aggregating data, and using linked tabs can help, but they come with trade-offs in time, accuracy, and usability. For teams ready to expand their toolkit, solutions like Gigasheet provide scalable pivot table capabilities, live data connections, and ad hoc analysis without the limitations of traditional spreadsheets.
Spreadsheets will always be a vital tool for data analysis, but as data volumes grow, exploring alternative platforms can streamline workflows and unlock faster insights. Whether you’re working with Snowflake, Redshift, or BigQuery, consider tools that support large-scale pivot tables for a more efficient approach to data analysis.
Comments