



How to Create Pivot Tables in Databricks and Alternative Solutions for Excel Users
- Spreadsheet Hacker
- Dec 17, 2024
- 4 min read
Creating pivot tables is an essential part of data analysis. They help us condense, summarize, and visualize data effectively. While many are familiar with tools like Google Sheets or Excel for their flexibility, Databricks offers a unique approach for those looking to perform similar tasks at data warehouse (or lakehouse) scale. This guide will walk you through creating pivot tables in Databricks while recognizing its limitations compared to traditional spreadsheet tools. Don't know how to code or aren't able to use SQL? Fear not - we'll explore alternative solutions for users accustomed to Excel or Google Sheets.
Understanding Databricks and Its Query Language
Databricks is a cloud-based data platform that integrates with Apache Spark. It is widely used for large-scale data processing and analytics. Utilizing a SQL-like query language, Databricks allows users to manipulate and analyze data efficiently. For those skilled in Excel or Google Sheets, transitioning to Databricks may present a learning curve due to its different interface and functionality.
For example, a study found that around 70% of Excel users report facing challenges when moving to cloud-based applications like Databricks.
Steps to Create a Pivot Table in Databricks
Step 1: Setting Up Your Environment
Log into Databricks: Access your Databricks workspace. If you don't have an account, sign up for a free trial or explore other plans that fit your needs.
Create a Notebook: After logging in, create a new notebook to write the code for generating your pivot table.
Prepare Your Data: Load your dataset into a DataFrame. You can read data from various sources such as CSV, JSON, or databases. For example, you might load sales data for over 1,000 transactions like this:
data = spark.read.csv("path_to_your_file.csv", header=True, inferSchema=True)Step 2: Grouping Data
Next, group your data by one or more categories. For instance, if you are analyzing sales data, you could group it by the "ProductCategory":
grouped_data = data.groupBy("ProductCategory")This process is similar to how users would segment their data in Excel.
Step 3: Aggregating Data
Once your data is grouped, use aggregation functions to generate summarized values. If you wanted to calculate total sales and average discount per category, you would do it like this:
pivot_table = grouped_data.agg({"Sales": "sum", "Discount": "avg"})Using this method allows you to compute totals, average discounts, and other relevant statistics efficiently.
Step 4: Reshaping Data (Pivoting)
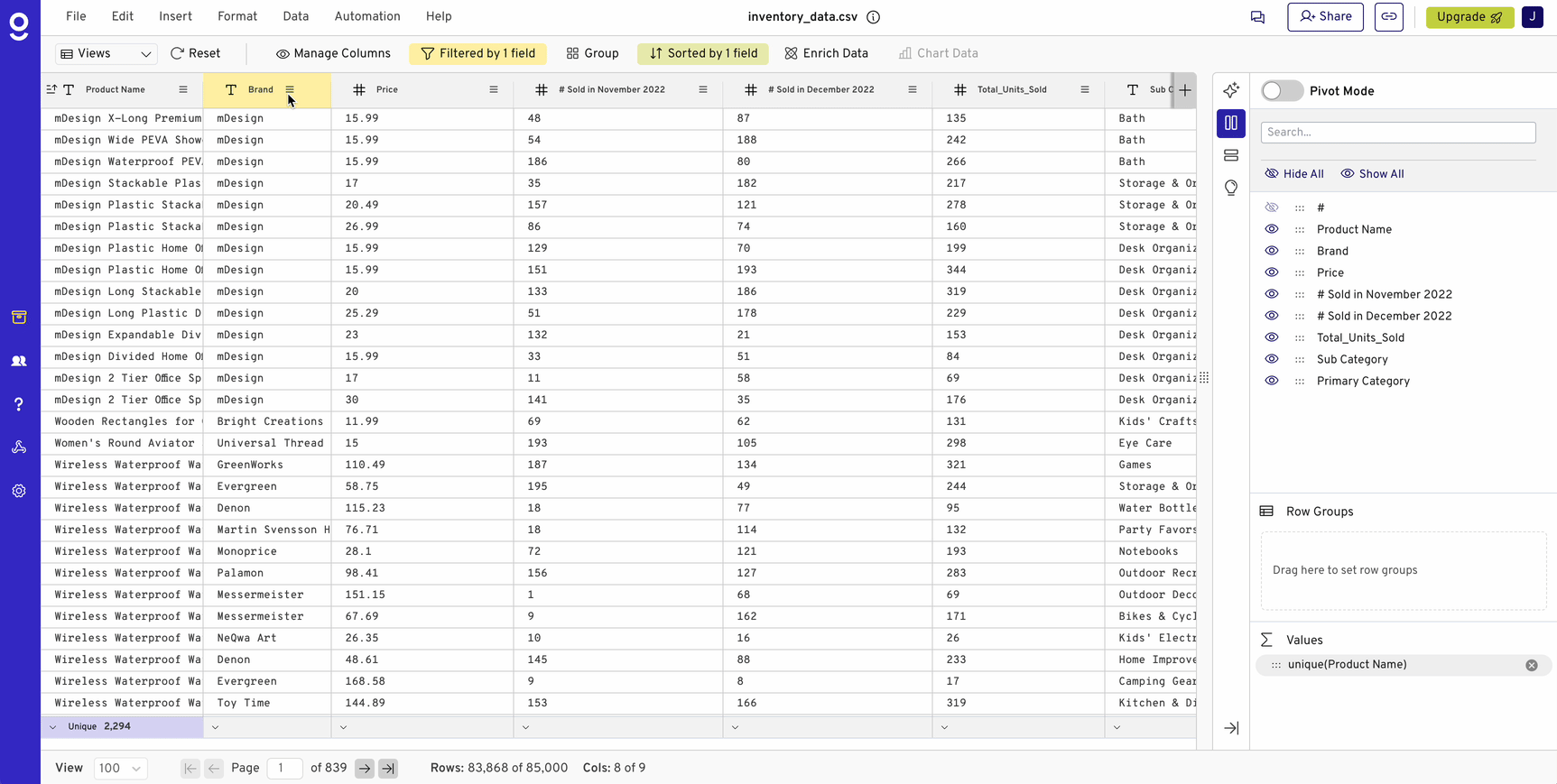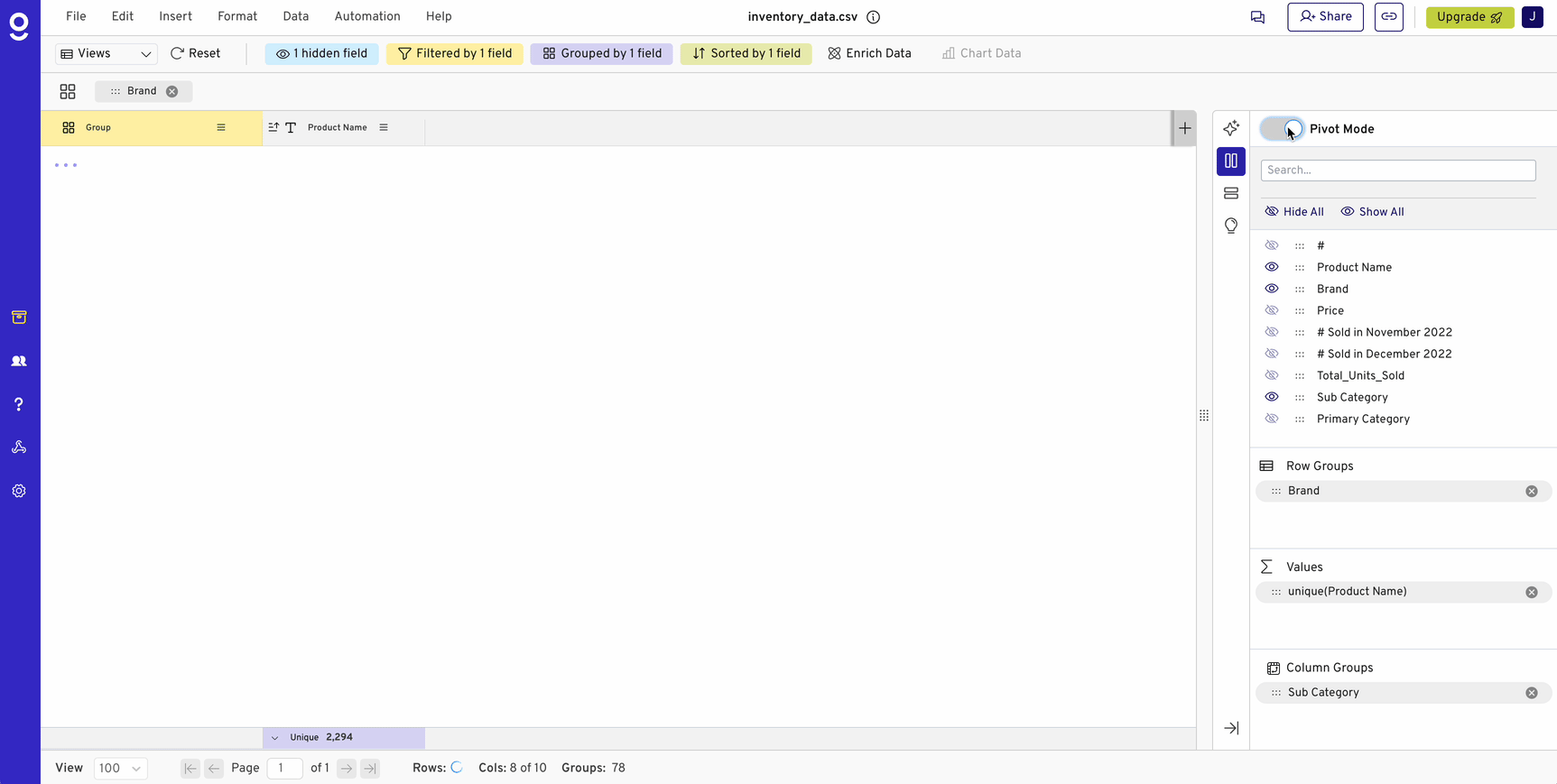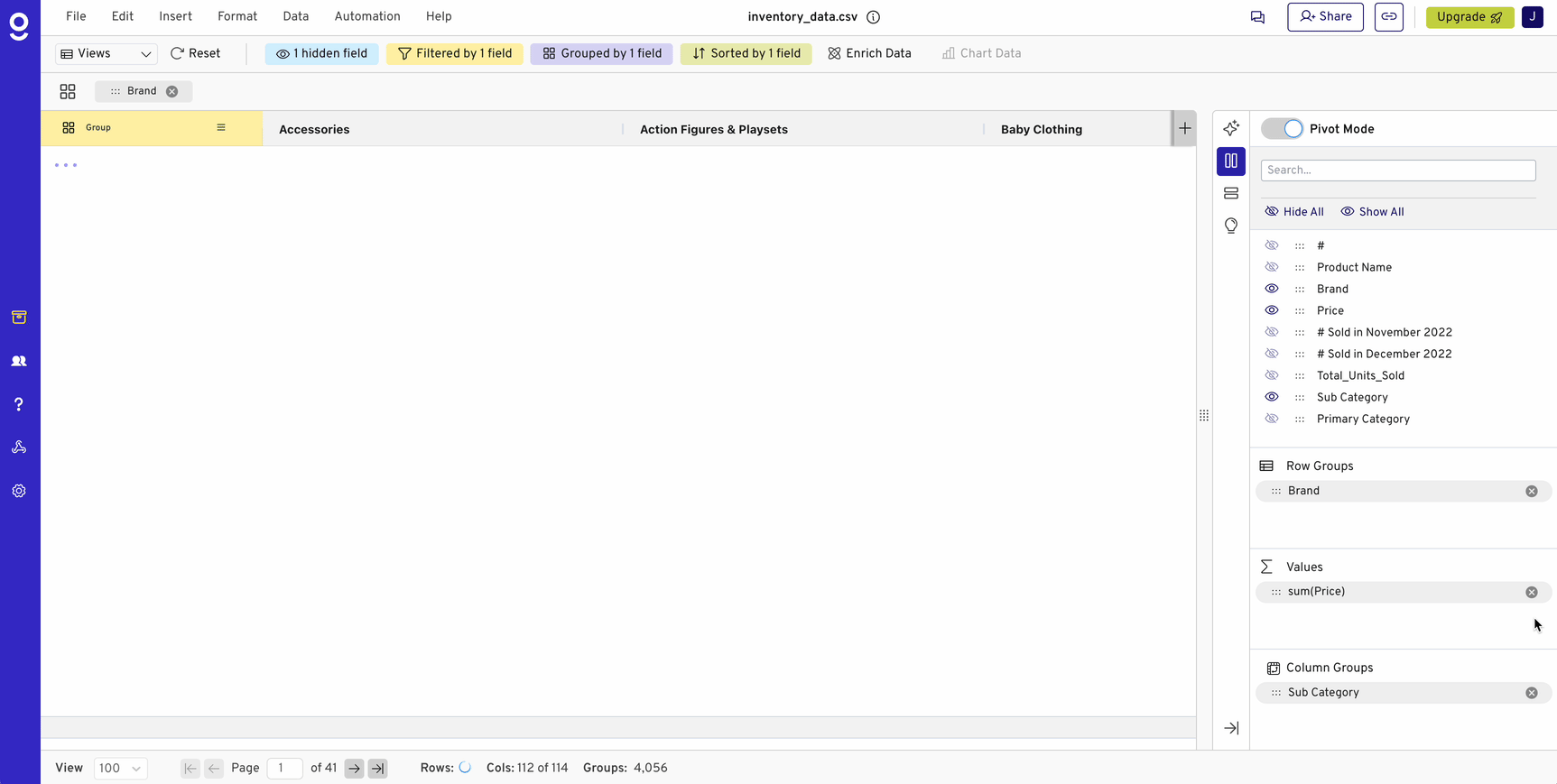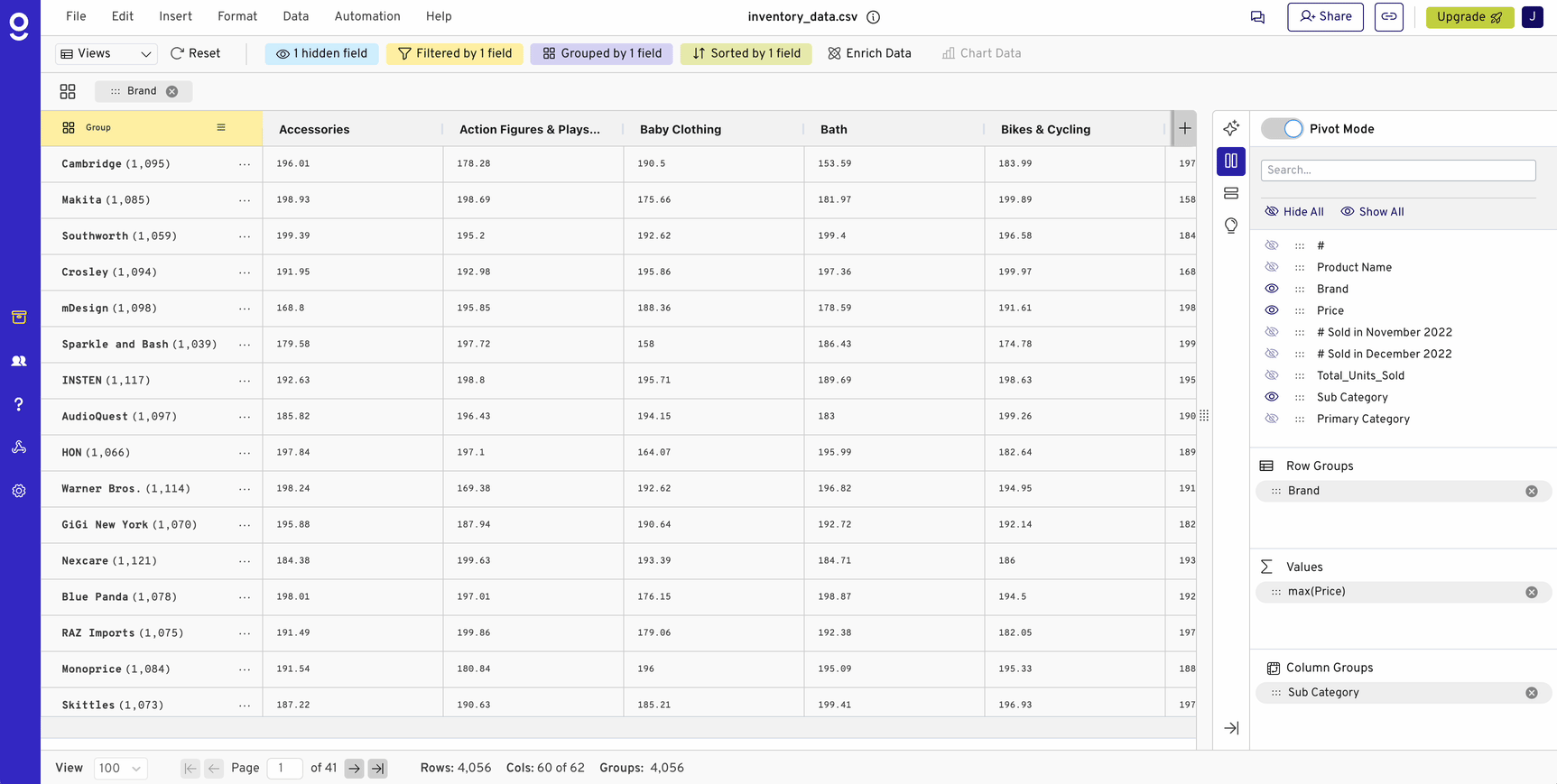
To reshape your grouped data into a pivot table format, use the `.pivot()` method. Say you want to create a pivot table that shows total sales by category and month:
pivot_table = grouped_data.pivot("Month", "ProductCategory", "sum(Sales)")This command will provide a pivot-style table of sales totals across different categories for each month.
Step 5: Displaying Your Pivot Table
Finally, to view your pivot table result, execute the following command:
pivot_table.show()This will display your summarized data in a clear format.
Limitations of Pivot Tables in Databricks
While pivot tables in Databricks are functional, there are key limitations:
Less Flexibility: Unlike Excel and Google Sheets, which allow users to manipulate rows and columns interactively, Databricks takes a code-oriented approach that may seem less inviting. For example, Excel allows for quick visual adjustments, while Databricks requires understanding code to make similar changes.
Limited Visualizations: Although Databricks increasingly offers some visualization options, these can be less comprehensive/flexible than the graphical features available in typical spreadsheet applications. For instance, users might find that Excel's chart types exceed those currently available in Databricks.
Workarounds for Excel Users
For Excel users who find Databricks’ pivot tables cumbersome or inadequate, there are several alternatives:
Exporting Data: Export data from Databricks to Excel or Google Sheets. This allows you to combine Databricks’ processing power with the user-friendly features of spreadsheet software. In 2023, approximately 60% of data analysts reported using this hybrid approach in their workflows. (Just be mindful of Excel row limits, and Google Sheet's even tighter cell limits.)
Using Jupyter Notebooks: If you are comfortable with coding, Jupyter notebooks with PySpark can offer a smoother experience for data manipulation and similar pivot functionalities. A 2022 survey indicated that about 30% of data professionals prefer using Jupyter alongside Databricks for its streamlined interface.
Adopting Gigasheet Enterprise: Gigasheet for Databricks is an excellent alternative for pivot tables in Databricks on larger datasets while maintaining a user-friendly interface. It allows you to work with massive amounts of data while offering functionalities similar to traditional spreadsheets. As of 2023, Gigasheet has reported an increase in user adoption by 50% among data analysts seeking easier data handling.

Navigating Data Analysis with Databricks
Creating pivot tables in Databricks may not offer the same ease of use that Excel and Google Sheets users are used to. However, by following these steps, you can effectively summarize and analyze large datasets while keeping in mind the platform's limitations.
For users looking for more flexibility and visual options, consider exporting your data to other applications or utilizing alternatives like Gigasheet Enterprise. The right choice depends on your specific needs in data analysis and your comfort level in transitioning from one tool to another.
Comentarios